-
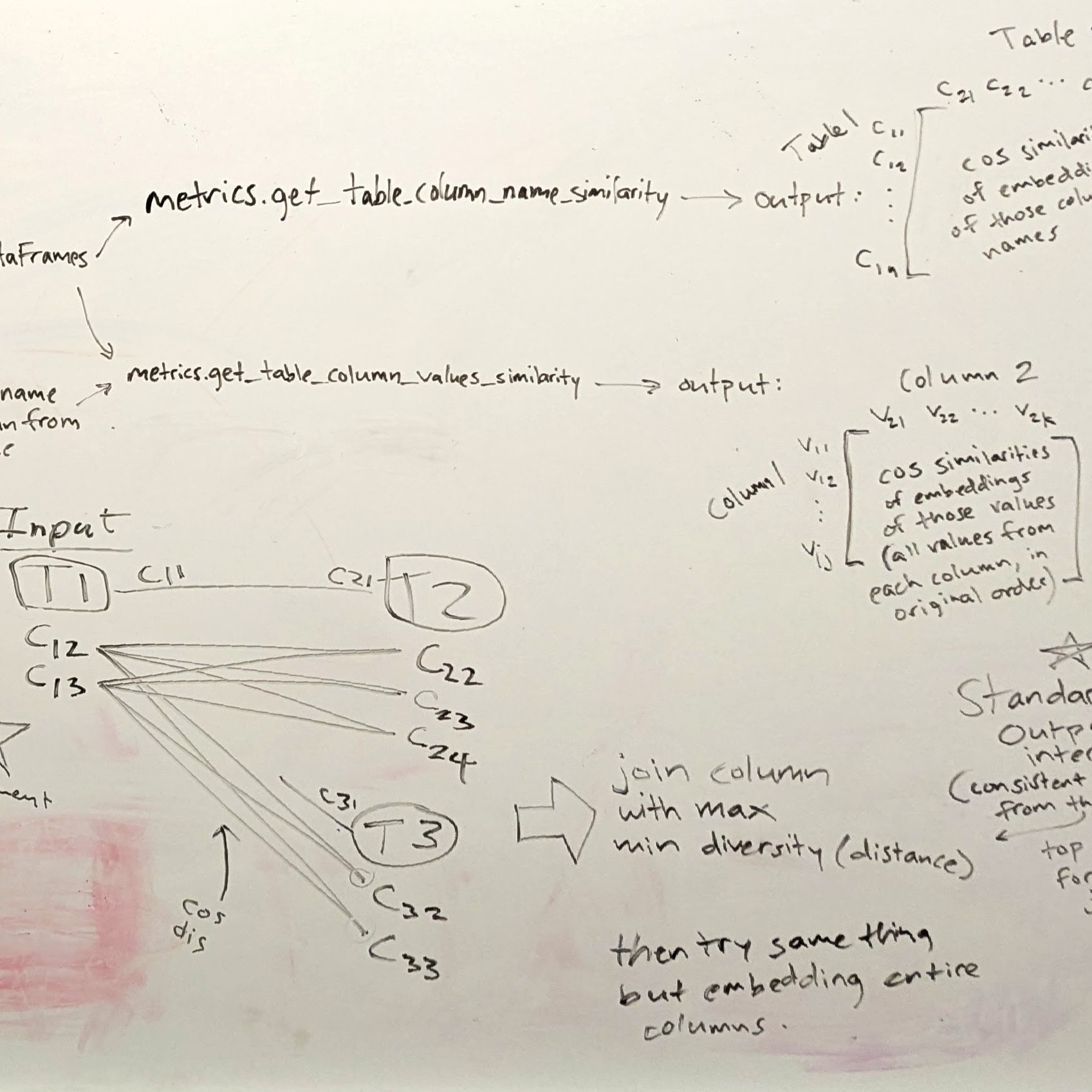
Semantic Tuple Diversification
Designed and built a system that finds tables in a data lake that can be joined to a user-provided table and suggests string columns to add based on their semantic difference from the user’s table.
I undertook this project with two of my classmates under the direction of Dr. El Kindi Rezig of the Kahlert School of Computing at the University of Utah, whose research often focuses on algorithmic solutions to the messy, tedious of data engineering, such as data discovery, data integration, and the management of large-scale data lakes. Our goal was to build a system to address the following scenario: a user has a table with information of interest to her, she would like to expand it by adding more columns, and she must find these columns amid a data lake of tables with inconsistent schemas. In addition, she would like to ensure the columns she adds bring in as much new information as possible, so the system must measure semantic, not merely syntactic, differences between strings.
Our system identifies plausible joins, builds a join graph, identifies string columns from the joinable tables, quantifies how much semantic diversity (meaningful new information) each candidate string column would add to the existing dataset, and ranks candidate columns from most to least diversity added. In short, it surfaces columns from the lake most likely to give the user new information about the entities in his table.
My contribution to the project code was the join graph builder, which was challenging in its own right but was only the initial requirement for solving our overarching goal. I did not write any code for embedding columns, quantifying diversity, ranking the columns. However, each step was a cooperative creative process; I spent about 20 hours with my teammates throughout the semester discussing theory and pseudocode about how to solve these problems, during which I contributed several of the key ideas that led to our solution. I also went through all the project code in detail with my teammates when were finished, so even though I didn’t write all of it, I have a thorough understanding of the finished system.
See a demonstration of the system and our complete report below.

The result of our first brainstorming session—our first attempt to outline a complete solution (handwriting mine) Demonstration
Final report
-

Drive for Show, Putt for Dough
How accurate is the famous saying? (a web app using Flask and Plotly)
-
Clustering Medical Conditions by Prescribed Drug
Exploring relationships between medical conditions and the drugs prescribed for them using data from the 2023 Medical Expenditure Panel Survey.
Data Processing
1) By joining the MEPS Medical Conditions file (COND) and the Prescribed Medicines file (RX) via the Condition-Event Link file (CLNK), we created a dataset where each row was a prescription event: one instance of a person filling or refilling a drug, including the name of the drug and for what condition it was prescribed. (281,158 rows, 11 variables.)
2) After removing refills (so each patient–drug–condition combination was counted only once), removing rare conditions and drugs (<25 occurrences), and aggregating the drugs into 16 therapeutic classes, we created a condition–drug co-occurrence matrix: each of the 206 rows was a condition, each of the 16 columns was a drug class, and each cell held the number of times they occurred together in a prescription event. This matrix answers the question, “How many people in the sample were ever prescribed a drug in class D for condition C?”
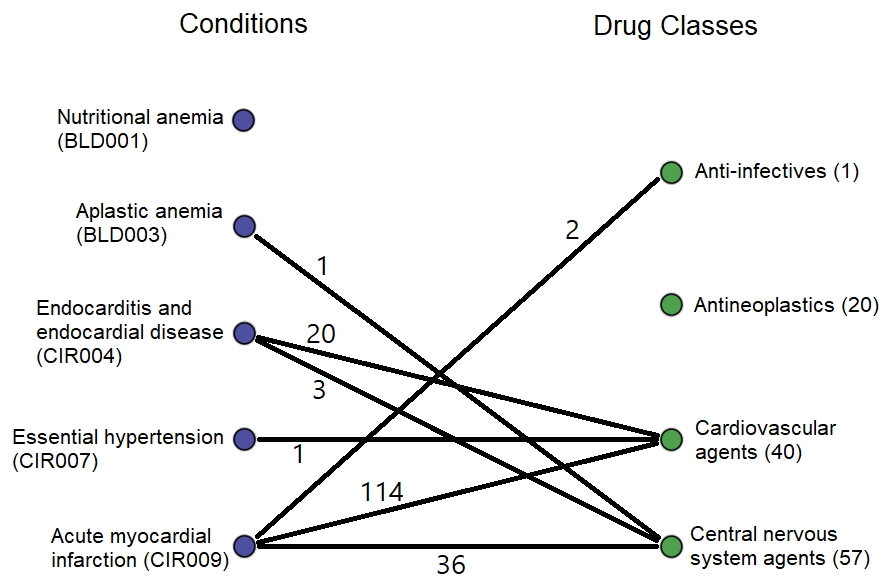
Conceptually, this matrix represents a bipartite graph connecting conditions to the classes of drugs prescribed for them, with edge weights equaling the number of people to whom such a prescription was given. That graph would look like this, but with 201 more conditions and 12 more drug classes (the weights are from the real data).
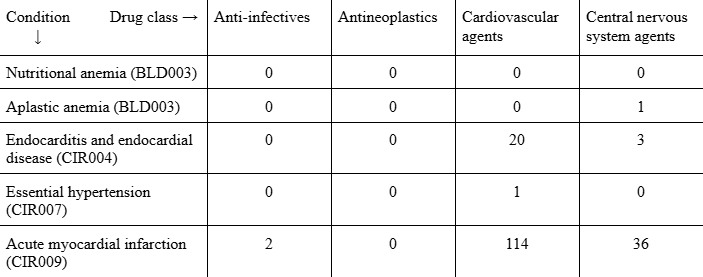
Literally, the matrix looks like this (with 12 more columns and 201 more rows).
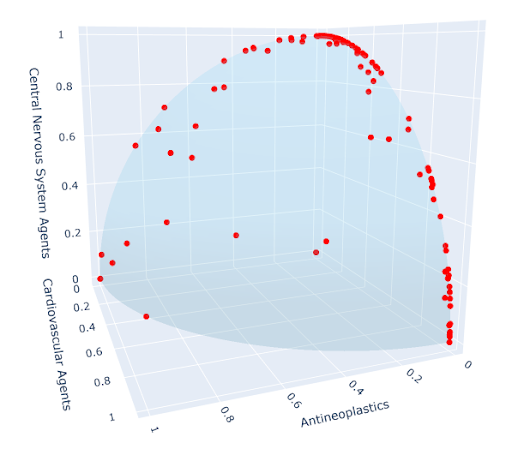
3) Since we were interested only in which drugs were typically prescribed for each condition, not how often the conditions occurred, we performed a final step: normalization. After normalization, each vector has an L2 norm of 1, so the data can be visualized as points on the unit sphere in 16 dimensions, all lying in the positive orthant or on an axis bordering it. Using only the first three dimensions, we get the figure at left; try to envision the impossible, an analogous figure in 16 dimensions, and you’ll have a good understanding of the final data structure.
The higher the value of a coordinate, the more often drugs of that class are prescribed for that condition.
Clustering
We used three clustering methods:
- K-means
- Hiearchical agglomerative clustering (HAC)
- Mixture of von Mises–Fisher distributions (vMF) (I was responsible for this model, which I borrowed from Banerjee, Arindam; Dhillon, Inderjit S.; Ghosh, Joydeep; Sra, Suvrit (2005). Clustering on the Unit Hypersphere using von Mises-Fisher Distributions. Journal of Machine Learning Research, 6, 1345–1382.)
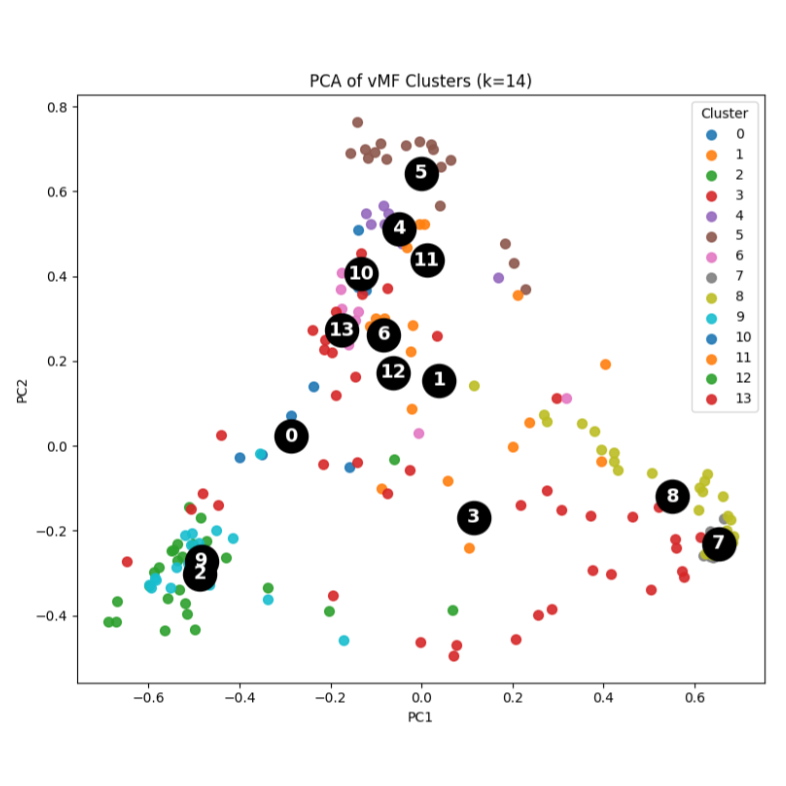
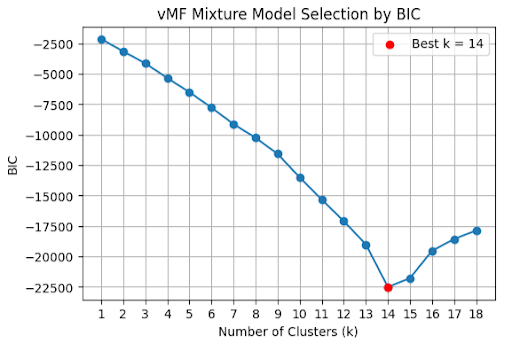
Using BIC, the optimal number of clusters was 14 (click to show plot).
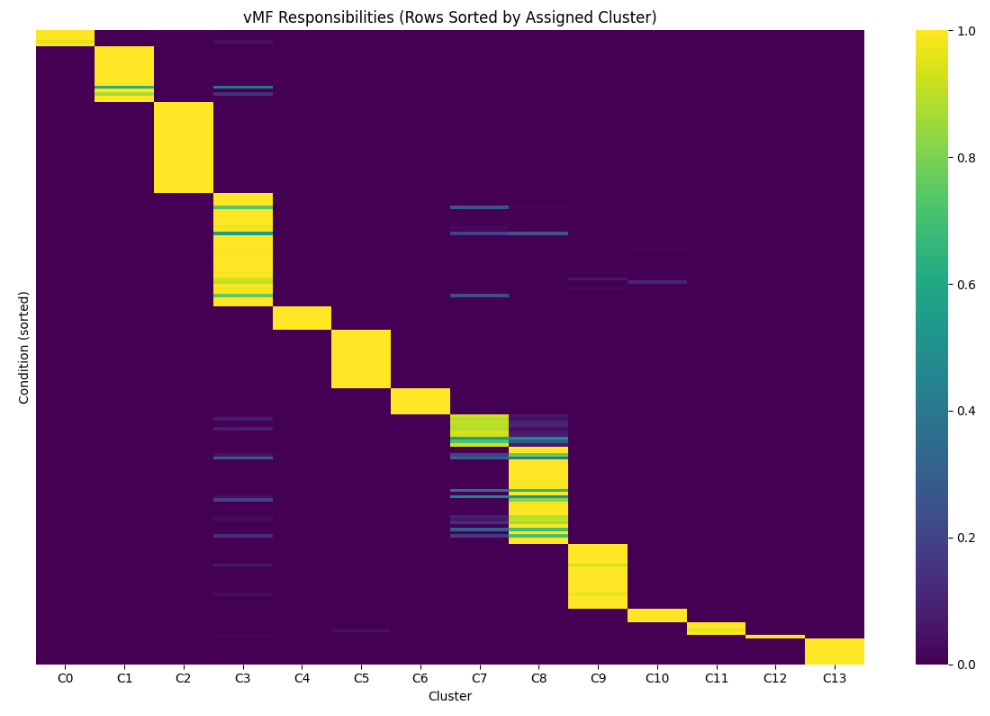
The soft cluster assignments were mostly confident, but there is some uncertainty about the boundaries between a few of the clusters, most notably 3, 7, and 8 (click to show plot; the lighter the color, the higher likelihood the point represented by the row belongs to the cluster represented by the column).
At right (or below, on mobile) is an example cluster. For each cluster, we found the mean vector—the “characteristic condition” of that cluster—and used it to identify the cluster’s typical prescription pattern. The number in parentheses is the coordinate, representing how frequently the drug class is prescribed for conditions in the cluster. (Keep in mind the coordinates don’t have a meaningful unit; the most specific valid interpretation is “higher means more frequent.”)

All three methods produced similar clusters with similar themes. We identified cluster themes manually by looking at the types of conditions in them and the types of drugs most germane to it, then we had an LLM do the same exercise to verify our conclusions. These, roughly, were the cluster themes (the numbers are arbitrary, just identifiers):

Click here to see the complete set of clusters.
Takeaways
Most of the analysis validates common-sense conclusions. Of course most respiratory conditions are treated similarly, predominantly with respiratory agents; of course most gastrointestinal conditions are treated similarly, predominantly with gastrointestinal agents; etc. Where clusters are clean, no questions are raised.
Three of the clusters are less clear. To me, these are the interesting ones. I’ll conclude with a few potential questions:
The division between cluster 7, which we’ve informally labeled as “central nervous system (CNS) disorders,” and cluster 8, which we’ve called “mental health conditions,” is blurry. (In fact, k-means and HAC didn’t even make them distinct clusters.) Cluster 7 is treated almost exclusively by CNS agents, while cluster 8 is treated primarily by CNS agents but also has a very common secondary drug class: psychotherapeutic agents. Why are these clusters so intertwined? It would be satisfying if, waiting to be unearthed here, there were two clusters with different primary drug classes: one for conditions best treated by CNS agents, and one for conditions best treated by psychotherapeutic agents. Can further study of these conditions reduce the variation in how cluster 8 is treated, leading to the emergence of two distinct groups?
Cluster 3 is the largest, has the largest variety in prescriptions, and has many low-confidence assignments. K-means and HAC both produced a similar cluster. This cluster is a sort of mixed bag: no strong unifying type of condition, no strong unifying treatment. Every condition in this cluster, then, raises questions of its own. If there isn’t a consistently applied treatment method, it implies a strong, effective treatment method isn’t known (or else it would be used consistently); can one be discovered? Or, if a condition in this cluster does have a consistent treatment, then it’s categorized here because there are few or no similar conditions, begging the question “what makes that condition so unusual?”
-
Android Malware Classification Pipeline
A Scikit-learn data transformation and model training pipeline comparing the effectiveness of four machine learning models on a classification task with sparse data.
-

Knot Invariants Research Using Supervised Learning
Created a custom encoding for the Jones polynomial and used it to predict other knot invariants with the Keras Sequential API.
As a junior at BYU, I was hired by a research group in the mathematics department headed by Dr. Mark Hughes, who specializes in low-dimensional topology, including knot theory. Knot theory involves more data than most areas of pure mathematics research—a theoretically infinite number of knots, thousands of which have been characterized and catalogued, each described by dozens of mathematical attributes (“invariants”)—so he created the research group to explore data-oriented approaches to the study of knots.
The question that came to occupy most of my time was this: could machine learning uncover unexpected interactions among knot features? In other words, could it identify large-scale patterns in knot invariants that, according to known theory, should not be there? If so, it would hint at latent mathematical structure that topologists could then investigate.
I used KnotInfo1, a database of all 12,965 prime knots with crossing number up to 13 and all their known invariants.2 (A prime knot is one that isn’t made by connecting two smaller prime knots; the crossing number is the minimum number of crossings in any diagram of the knot). Most invariants are known for lower-crossing knots, but as the number of crossings grows, so does the difficulty of calculating invariants; thus, not every knot in the database has a value for every invariant. But there’s enough to work with. I also used Matlab code Dr. Hughes had previously written to pseudo-randomly generate knots of arbitrary crossing number, so our dataset could include knots larger than crossing number 13.
All invariants included (if known) for each knot in the KnotInfo database Here are the details for the approach that proved successful (meaning that among a lot of predictable, boring results I found a single unpredictable, interesting one). I set out to see if I could accurately predict any of a knot’s invariants using only its Jones polynomial.
Data Validation
First I filtered out knots for which the Jones polynomial was not definitively known—in KnotInfo, where the lower bound did not equal the upper bound, or in the generated dataset, where the Jones calculation returned “failed.”
Encoding the Features
Example Jones polynomial:
Since Jones polynomials are strings, I had to parse them into a format machine learning models could accept. I wrote a custom parser to turn them into lists where the index corresponds to the exponent, in the order 0, 1, -1, 2, -2, …, and the value is the coefficient. The example above would have become [3, -3, -3, 2, 3, -1, -1]. Each list index becomes its own feature column.
Different knots have different Jones polynomial lengths, so I padded the end of each list, appending zeros until each was as long as the longest list in the dataset. Generally, filling missing values with zeros would be bad practice, but in this case it is an appropriate solution; each list element represents the coefficient of one term in a polynomial, so a list element being nonexistent is mathematically equivalent to it being zero (e.g., x^2 = x^2 + 0x + 0). This made the inputs consistent and ready to input into a neural net.
Model Setup
Since I wanted to predict as many invariants as possible using only the Jones polynomial, I made it so I could pass in the name of an invariant and a model would train using Jones as the input and the named invariant as the target. This was a baseline framework I would have expanded had I stayed with the research group longer; every invariant, some with various possible encodings, could have been either an input or an output of this generalized model pipeline, and I then I could have compared every 1:1 input:output combination, or which combinations of invariants were more predictive than any one alone.
I first used Jones to predict all the integer invariants, since those were the easiest to encode; you can either treat them as numbers or treat them as categories using a label encoder, and both are simple to set up. My model architecture was a simple neural network using the Keras API over TensorFlow, trained independently for each target invariant. These were my prediction accuracies on each test set:

From here, my ability to contribute was nil; I had no training in topology, so I didn’t know what any of these invariants were or whether evidence of their connection to the Jones polynomial was significant. I emailed the results to Dr. Hughes’s, who said the connection between the Jones polynomial and the Arf invariant was well known, but the result for Genus-4D was a little more suprising. Additionally, he later discovered a bug in his Matlab code that was causing it to produce invalid knots, and once it was fixed, the accuracy of 4D genus predictions jumped even higher, to 97.7%.
Unfortunately, I left the research group soon afterward, but Dr. Hughes told me it continued to be a significant research question for him for some time. A group of physicists in South Africa he worked with expressed interest in the connection with the 4D genus, and he sent my results on to them for further testing. Meanwhile, I got a new job, and I lost the trail of the research. But it was fun while it lasted!
Code